Aanmaken van de Mysql databank microservice
Een databank gebruiken als microservice is eigenlijk meteen al werken met een uitzonderingsgeval. Er zijn namelijk veel goeie redenen te verzinnen om Mysql nu net niet als microservice te deployen. (welke?) Daarom zal in praktijk meestal gebruik gemaakt worden van een managed service (zoals Cloud SQL, AWS RDS, AWS Aurora, ..) of een dedicated server.
Voor dit lab doen we het toch, om kosten te besparen én als voorbeeld om ook de andere diensten op te zetten (Wordpress zelf).
Voor Mysql zullen we verschillende kubernetes-componenten nodig hebben:
- een deployment (die de pods beheert),
- een service (die de dienst beschikbaar stelt voor andere microservices in de cluster),
- een secret file met wachtwoorden
- een persistent volume: hiermee maak je een stukje persistent storage aan. (te vergelijken met een 'virtuele hard disk') Je kan naast de grootte bijvoordbeeld ook de storage-class kiezen: ssd/hdd/... Indien dit niet gedefinieerd wordt, zal automatisch een persistent volume aangemaakt worden.
- een persistent volume claim: met een pv-claim reserveer je een stuk van het persistent volume, dat je dan kan gaan koppelen aan een microservice. In dit deel van de opgave wordt het gebruikt om de databestanden van mysql op te bewaren zodat deze ook na het herstarten van de container bewaard blijven.
Het kubectl commando kan je gebruiken om de bestanden toe te passen op je cluster:
kubectl apply -f <filename.yaml>
Twee van die componenten krijg je van ons:
- de deployment (download hier)
- pv-claim. (download hier)
Probeer de bestanden volledig te begrijpen voor je ze gaat toepassen op je cluster.
Vanwege de afhankelijkheden die er zijn, deploy je ze best in de juiste volgorde. de deploymentheeft de secret én de persistentvolumeclaim nodig, die pas je dus best eerst toe.
Beschrijving van de deployment
In deze deployment zie je de afhankelijkheden van persistente storage (voor een mount naar /var/lib/mysql) en de afhankelijkheid van een secret voor de omgevingsvariabelen.
apiVersion: apps/v1 <1>
kind: Deployment
metadata:
name: mysql
namespace: mijnblog <2>
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6 <3>
name: mysql
env:
- name: MYSQL_PASSWORD <4>
valueFrom:
secretKeyRef: <5>
name: dbcredentials
key: mysql_password
- name: MYSQL_USER
valueFrom:
secretKeyRef:
name: dbcredentials
key: mysql_user
- name: MYSQL_DATABASE
valueFrom:
secretKeyRef:
name: dbcredentials
key: mysql_database
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: dbcredentials
key: root_password
ports:
- containerPort: 3306 <6>
name: mysql
volumeMounts:
- name: mysql-persistent-storage <7>
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage <7>
persistentVolumeClaim:
claimName: mysql-pv-claim
-
Momenteel wordt binnen kubernetes de apps/v1 api versie gebruikt voor de meeste componenten. Opgelet dus als je een oud voorbeeld vind op internet: mogeljks gebruikt die nog een oude (niet meer ondersteunde) versie van de API. Vaak zijn de verschillen tussen de api-versies erg klein overigens.
-
Vergeet dus niet in alle bestanden de namespace expliciet te vermelden
-
Hier geef je aan welke container moet gebruikt worden. In dit geval gaat het over mysql, met als tag 8. Deze vind je (en dus ook de documentatie) op https://hub.docker.com/_/mysql
-
Welke variabelen je kan meegeven wordt bepaald door de container die gebruikt wordt, in dit geval is dat de basic mysql container
-
Deze variabelen komen uit een secrets-file, die je dus nog moet aanmaken.
-
Deze container is voor andere diensten binnen de cluster via poort 3306
-
Met
volumeMountsgeven we aan dat een bepaalde map moet gemount worden. De naam die je geeft (mysql-persistent-storage) kan je kiezen, maar moet wel identiek zijn aan wat je onderaan het bestand kiest bij 'volumes'.
Beschrijving van het persistent volume
Intern zal mysql de databank bestaan uit een set van bestanden. Om te vermijden dat die verdwijnen bij het verlies van een deployment, plaatsen we deze op een 'persiste' disk. Dat is een reservatie van diskspace op een disk. Bij het aanmaken van zo'n reservatie (of 'claim') zal op de achtergrond effectief ook een persistent volume (= virtual hard disk) aangemaakt worden. Ga in de cloud console op zoek naar deze disk.
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim <1>
namespace: mijnblog <2>
spec:
accessModes:
- ReadWriteOnce <3>
resources:
requests:
storage: 5Gi <4>
- naam van het volume
- alweer, niet vergeten: altijd namespace vermelden
- access mode: deze bepaalt als meerdere hosts kunnen lezen/schrijven naar het volume.
ReadWriteOncebetekent dat slechts 1 host tegelijk kan lezen en schrijven. Dat is een grote beperking, want als je meerdere hosts in je cluster hebt zou je deployments die hier aan gekoppeld zijn dus allemaal op dezelfde host moeten plaatsen. Deze rechten verschillen per provider. Raadpleeg zeker het overzicht op https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes om te zien welke mogelijkheden er zijn. ReadWriteMany heeft altijd de voorkeur, maar zoals je in het overzicht ziet zijn er amper providers die deze op het moment van schrijven aanbieden. (of ze zijn erg duur in gebruik) Hou hier met je architectuur rekening mee. Dit kan op zich al een goeie reden zijn om mysql niet in K8S te draaien. - grootte van de virtuele schijf (5 gigabyte in dit geval)
Aanmaak van de secrets
Maak de secrets aan, ook hier zal je een yaml file voor nodig hebben. Hou je uiteraard aan de variabelenamen die je vindt in de deployment. Er zijn tal van manieren om dat te doen, werken met 'stringdata' is vermoedelijk het eenvoudigst. De Kubernetes documentatie kan je daarbij helpen. Welke variabelen je moet aanmaken kan je afleiden uit de deployment.
Het secrets-object moet als naam dbcredentials hebben, want daar wordt naar verwezen in je deployment file.
Alweer opgelet: maak dit aan in de juiste namespace..
Toepassen van de configuratie
Als je de configuratie in de juiste volgorde toepast, dan zou de mysql deployment actief moeten zijn.
Als troubleshooting nodig is, dan kan je de logs raadplegen. Die geven meestal een goeie indicatie van waar je fout kan zitten.
Aanmaak van de service
De databank zullen we nodig hebben vanuit andere microservices. Maak dus ook een service.yaml file aan. Die zal kort zijn, als naam gebruik je mysql. Als selector kan je verwijzen naar het app-label in de deployment (dat ook op mysql staat).
Dit kan je uiteraard opnieuw doen met een yaml file, maar eens je een werkende deployment hebt, kan je dit ook aanmaken via de 'expose a deployment' wizard in de GCP console.
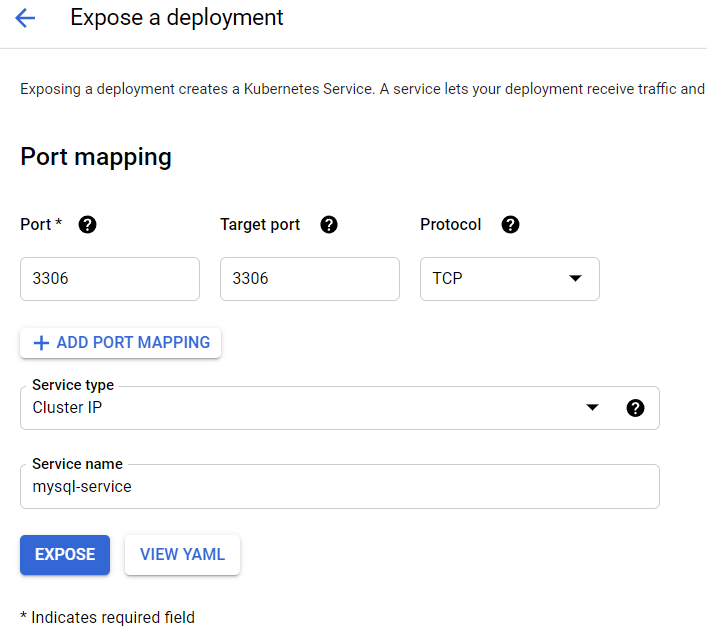
Als je deze weg gebruikt, bekijk en bewaar dan zeker de resulterende yaml... Let er op dat je de service aanmaakt met als type 'clusterip'.